Table of Contents
Not too long ago, Facebook unveiled Graphql. This was thought up to be a flexible data access layer designed to work as a simple interface on top of heterogeneous data sources. Not long after facebook had introduced it, github announced that the latest version of its API (version 4) would indeed be a GraphQL API. Many other companies have followed including Meteor, Pinterest, Shopify to name a few.
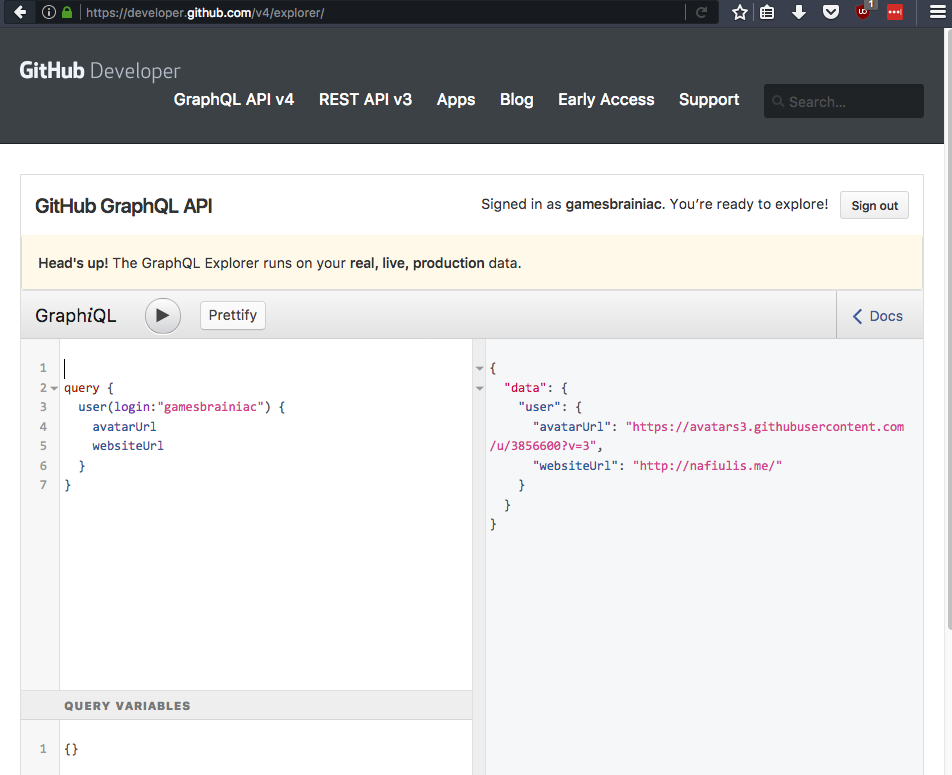
At its heart, Graphql is designed to replace REST APIs. It also has a proper specification so that developers aren't constantly fighting over the proper definition of Graphql. It has documentation inbuilt, with its powerful graphiql query application that allows people to quickly check out the results of a particular query, and get code completion on the fly, as they are writing the query.
Getting Started
Python's main competitor in the ring is a nifty little library called graphene. But before we get into graphene, we need to talk about some of the fundamental parts of Graphql.
- The model is an object defined by a Graphql schema.
- The schema defines models and their attribute.
- Each attribute of a model has its own resolver. This is a function that is responsible for getting the data for that particular model attribute.
- A query is basically what you use to get or set data inside Graphql
- Mutations are particular queries that allow you to change the data for a given model or a set of models.
- Graphiql is the UI that you use to interact with a Graphql server. The IDE-like thing that you see in the above screenshot is the Graphiql interface.
Here Comes Python
Python's attempt at Graphql can be broken down into three parts. Graphene, ORM specific graphene add-ons and graphene libraries that add support to web frameworks such as flask or django. Graphene allows you to define your models, define the attributes in your model, and also parses queries to get the data for those particular models.
The ORM specific graphene libraries basically do the job of turning your SQLAlchemy or Django models into Graphql objects with the help of graphene. Some libraries will will also come in with views that fit in with your web framework like graphene-django.
Playing with Graphene
Installation is quite easy, and graphene supports both python versions 2 and 3.
pip install graphene
Once you've installed it, import it, write a simple model, and the execute it like so:
import graphene # 1
class Query(graphene.ObjectType): # 2
hello = graphene.String(description='A typical hello world') # 3
def resolve_hello(self, args, context, info): # 4
return 'World'
schema = graphene.Schema(query=Query) # 5
query = '''
query {
hello
}
''' # 6
result = schema.execute(query) # 7
In 1 we are importing the package. Note that in 2 we are creating the query class. All query classes inherit from the graphene.ObjectType class. You can also embed queries within queries (this is great when you want to modularize your applications). Furthermore, even complex objects will also inherit from graphene.ObjectType.
This class basically holds all the models. Right now, there is only one model, and that is hello, which happens to be a simple string. Yes, I know its not terribly exciting, but bare with me.
In 3 we add an object to the schema. In this case it is a simple string. In 4 we basically write the resolver for that particular model in the schema, we will get into the details of the function signature soon enough.
In 5 we basically declare the schema, and we tell it that the query class object is Query (a query object can be made up of multiple query objects, and we will get into that later).
Then, we declare the simplest query possible, in 6 and in 7 we finally execute it. This is what the result looks like:
In [6]: result = schema.execute(query)
In [7]: type(result)
Out[7]: graphql.execution.base.ExecutionResult
In [8]: result.data
Out[8]: OrderedDict([('hello', 'world')])
The result comes with three main attributes.
In [12]: result.data
Out[12]: OrderedDict([('hello', 'world')])
In [13]: result.errors
In [14]: result.invalid
Out[14]: False
data gives us the return data that we want. errors points any errors that we might [1] have and finally, invalid basically tells us that if the query itself is valid.
Basic Types
So, now that we've gotten the hang of the fundamental parts of the Graphql system, its time that we explored the other data types, and started playing around with more complex objects. There is already plenty of good documentation on this stuff, so I won't do a copy of the tutorials that are already available. The first thing to take a look at is the type reference.
There are quite a few types to go over, but in basic terms, there is a dichotomy between scalars and non-scalars. Scalars are the base object types, they are things like strings, integers, booleans etc. Non-Scalars on the other hand are more complex objects, often they are containers of scalars, like lists, graphene.List. They can also be interfaces, that other graphene ObjectTypes inherit from and of course, there are mutation types, that basically make changes on top of the data.
In simple terms, there are a lot of types, but what it comes down to are basically types that hold information, types that contain basic scalar types, types that other types inherit from in a concrete sense and types that other objects inherit from in an abstract sense. Pretty much what you'd expect from a simple object oriented system.
A Few Opinions
However, what I have come to notice is that it is almost always better to avoid using abstract types, and just go straight for interfaces. Most of the time, you just don't need abstract objects. In the case of Graphql, composition is almost always better than inheritance. Probably the only place that it makes sense to use the AbstractType class is for Query types that you are later on going to use in your final Query object.
Make sure to keep your names simple, and avoid using graphene.NotNull, because you can always set required=True for scalar types anyway. This is similar to what you get in other serializer libraries, so people looking at the codebase can see commonalities between graphene and other libraries.
Integration with ORMs
If you think about it, at its core, graphene is basically a combination of a serialization library and a Graphql query interpreter, so it would make a lot of sense for it to work with ORMs and it does so quite well. At the time of writing this, there is support for django, sqlalchemy as well as google app engine. Most are really quite simple to integrate. Most of the time, you just have to set the meta model attribute of an object type and you're done.
Django
from django.db import models
from graphene_django import DjangoObjectType
class Account(models.Model):
birth_date = models.DateField(db_column='personbirthdate', null=True)
created_date = models.DateTimeField(blank=True, null=True, db_column='createddate')
is_paying_customer = models.NullBooleanField(db_column='iscustomer')
country = models.CharField(db_column='country', max_length=3, null=True, blank=True)
customer_number = models.CharField( db_column='cnumber', unique=True, max_length=255,
blank=True, null=True, editable=False)
class Meta:
managed = False
db_table ='accountinfo'
class AccountType(DjangoObjectType):
class Meta:
model = Account
You can now use AccountType just like you would any other object type. But most of the time, you don't even have to manually add things to the query objects. If you have django-filter installed, you can do something pretty simple, and add graphene.Node to your list of interfaces for a give type. This allows you to set some variables in the metaclass that allows for simple filtering and also allows your type to be easily integrated into the query using DjangoConnectedFilterField. Here's an example of what that would look like from the perspective of the Account model:
class AccountNode(DjangoObjectType):
class Meta:
model = Account
interfaces = (graphene.Node, )
filter_fields = [
'customer_number',
'is_paying_customer',
]
And this is what it would look like in the query object:
from graphene_django.filter import DjangoConnectedFilterField
class AccountQuery(graphene.AbstractType):
# Gives you a particular account
account = graphene.Node.Field(AccountNode)
# Gives you all the accounts available
all_accounts = DjangoFilterConnectionField(AccountNode, order_by='-customer_number')
This really simplifies your whole query process, and focuses on fat database models and not fat graphene objects. Note, that I use graphene.AbstractType for this AccountQuery objects because I'm basically going to use it as a mixin for my final Query Object. Here is what that looks like:
from .queries import AccountQuery
class Query(AccountQuery, graphene.ObjectType):
pass
schema = graphene.Schema(query=Query)
This way, your main query object won't be cluttered, and you can keep adding your queries as you please. Make sure to add graphene.ObjectType as the last argument for inheritance, otherwise your final Query object will not be a concrete class.
SQLAlchemy and Others
Other ORMs are also similarly supported. With SQLAlchemy, you just use SQLAlchemyObjectType instead of DjangoObjectType, you can also add the Node interface to it, and have a similar querying experience that you do with django using SQLAlchemyConnectionField. The same is true for google app engine. Peewee support is still in the works.
Integration with Web Frameworks
As you might expect, graphene supports a few popular frameworks, with more support coming. Right now there is awesome support for flask and django. Here is what a flask Graphql application looks like:
from flask import Flask
from flask_graphql import GraphQLView
from models import db_session
from schema import schema, Department
app = Flask(__name__)
app.debug = True
app.add_url_rule(
'/graphql',
view_func=GraphQLView.as_view(
'graphql',
schema=schema,
graphiql=True
)
)
@app.teardown_appcontext
def shutdown_session(exception=None):
db_session.remove()
if __name__ == '__main__':
app.run()
I would of course suggest that you have separate endpoints for graphiql and for your HTTP requests. You can also subclass GraphQLView if you want to add some custom authentication.
Final Thoughts
I really like Graphql, I've recently launched a production application based on top of Graphql, and graphene-django has really helped me replace my current REST API with a Graphql API (or service or whatever it is that you want to call it). The delcarative syntax makes it quite easy to use, and so there really is not much of a learning curve, especially if you've used serializer libraries like Marshmallow or DRF's serializers.
Currently, graphene is basically a python port of the Graphql nodejs package at version 0.6. I'm pretty sure there will be version bumps in the future as the library has a healthy following. It also supports all kinds of clients including the apollo client.
| [1] | You will always get back errors in a separate sub-object in a query if you have any. You will not get any errors in HTTP status codes. |