Table of Contents
Last month, I had a programming interview. It hadn't gone as I would've liked, but I did get asked a question that I found interesting. The question is deceptively simple, but has a lot of depth to it. Since I failed to solve the problem correctly in the interview, I decided explore the ways in which I could optimize my initially O(n2) solution.
After a few attempts at solving the problem from different angles, I've come to appreciate the importance of understanding complexity, as well as its limitations.
The Question
The question was simple:
Given a list of words L, find all the anagrams in L in the order in which they appear in L.
An Example
Given the input
["pool", "loco", "cool", "stain", "satin", "pretty", "nice", "loop"]
The desired output would be
["pool", "loco", "cool", "stain", "satin", "loop"]
in that order exactly.
Quadratic Time
The naive solution to this will give you an O(n2) algorithm. Be warned, the following code may burn your eyes.
Initial Solution
from collections import Counter
def anagram_finder(word_list):
_ret = set()
for word in word_list:
c = Counter(word)
for other_word in [w for w in word_list if w != word]:
if Counter(other_word) == c:
_ret.add(word)
_ret.add(other_word)
return [w for w in word_list if w in _ret]
if __name__ == '__main__':
print anagram_finder(["pool", "loco", "cool", "stain", "satin", "pretty", "nice", "loop"])
This is wrong on so many levels, I don't even know where to begin.
- The problem solves the solution in quadratic time meaning, for more computing power we throw at this the slower it gets per computer. Imagine if we were to put an algorithm like this in the server, we would have serious scaling issues.
collections.Counteris expensive. It needs to create a dictionary, then it needs to add each character to the dictionary, that means hashing each character.- It adds the original word every single time it finds an anagram, and relies on
setnot to add duplicate values.
I'm probably missing a few points but the point remains; this is seriously bad code.
Linear Time
So, how can we turn this problem form an O(n2) solution into an O(n) solution? Using hash-maps correctly. Unfortunately, I did not come up with the brilliant idea of using a hash-map, but rather my interviewer told me that the way to get O(n) was to use a hash-map.
Hashing The Right Way
In general, whenever you hear the word "hash" you think md5 or SHA. But in reality, a hash is a way to map data in a uniform way. Think of it like this, if you have a the word pool and loop, in the eyes of the anagram solver, they are the same. Why? Because both words use the same characters. In other words, there had to be a uniform way to converting these two words into the same thing. If we were to simply sort the characters in the word, we'd get exactly what we're looking for. Here's a demonstration:
>>> sorted("loop")
['l', 'o', 'o', 'p']
>>> sorted("pool")
['l', 'o', 'o', 'p']
>>> "".join(sorted("loop"))
'loop'
>>> "".join(sorted("pool"))
'loop'
With that, I had my hashing function and with it, I had my linear solution.
def hasher(w): # 1
return "".join(sorted(w))
def anagram_finder(word_list):
hash_dict = {} # 2
for word in word_list:
h = hasher(word) # 3
if h not in hash_dict: # 4
hash_dict[h] = [] # 5
hash_dict[h].append(word) # 6
return [anagram for l in hash_dict.values() for anagram in l if len(l) > 1] # 7
if __name__ == '__main__':
print(anagram_finder(["pool", "loco", "cool", "stain", "satin", "pretty", "nice", "loop"]))
In 1, we create the hasher function. The hash is simple, it sorts the string alphabetically using sorted, which returns a list, which we then use as an iterable for "".join to create a string. We do this because python lists are not hashable (because they are mutable).
In 2, inside the anagram_finder function, we create a hash_dict, a dictionary for all our hashes. It must be pointed out that the dictionary, when adding new keys, will hash those keys as well.[1] The worst case for hasher is O(n) where n is the length of the word in question, so no issue with the size of the list we're given.
In 3 we actually call the hasher to hash the string. In 4, we check to see if this hash exists in the keys of hash_dict. If not, then we create a new list so that we can append words to it in 5.
In the end, we always append the word to the list of that key in 6. This means, that every key will always have at least one value stored in its list, and these values are the ones we don't one.
The simplified version of 7 is as follows:
_ret = []
for l in hash_dict.values():
if len(l) > 1:
_ret += l
The Pythonic Version
The above is great for explanation, but the pythonic version is much smaller:
from collections import defaultdict
def hasher(w):
return "".join(sorted(w))
def anagram_finder(word_list):
hash_dict = defaultdict(list)
for word in word_list:
hash_dict[hasher(word)].append(word) # 1
return [anagram for l in hash_dict.values() for anagram in l if len(l) > 1]
if __name__ == '__main__':
print(anagram_finder(["pool", "loco", "cool", "stain", "satin", "pretty", "nice", "loop"]))
We've made the code significantly smaller by using a defaultdict in 1. defaultdict allows us to give it a factory, in this case list, that will automatically create a list with a key if a key does not exist. If it does exist, then it will return that list, and we can append to it.[3]
But wait, we forgot about the ordering.
Ordering Done Right
We have a quick fix for the ordering, and that is simply to loop through all the words in the initial list and include only those that is in the list of anagrams. The solution is still O(n), but remains highly inefficient. One thought might be to use the collections.OrderedDict class. But although that might seem to work, the ordering will still not match the original in the case where anagrams are not next to each other. For example, the following piece of code will return:
from collections import OrderedDict
def hasher(w):
return "".join(sorted(w))
def anagram_finder(word_list):
hash_dict = OrderedDict()
for word in word_list:
hash_dict.setdefault(hasher(word), []).append(word)
return [anagram for l in hash_dict.values() for anagram in l if len(l) > 1]
if __name__ == '__main__':
print(anagram_finder(["nala", "pool", "loco", "cool", "stain", "satin", "pretty", "nice", "loop", "laan"]))
['nala', 'laan', 'pool', 'loop', 'loco', 'cool', 'stain', 'satin']
nala and laan should not be next to each other. This is because collections.OrderedDict remembers the order in which the keys were added.
So, in the end, I stuck to the following:
from collections import defaultdict
def hasher(w):
return "".join(sorted(w))
def anagram_finder(word_list):
hash_dict = defaultdict(list)
for word in word_list:
hash_dict[hasher(word)].append(word)
return [word for word in word_list if len(hash_dict[hasher(word)]) > 1]
if __name__ == '__main__':
print(anagram_finder(["nala", "pool", "loco", "cool", "stain", "satin", "pretty", "nice", "loop", "laan"]))
With that, we solved the ordering problem and still managed to make it linear.
Profiling
We never know how well something will actually work unless we profile it. So I got a big list of words[2] and go to profiling.
from collections import defaultdict
def hasher(w):
return "".join(sorted(w))
def anagram_finder(word_list):
hash_dict = defaultdict(list)
for word in word_list:
hash_dict[hasher(word)].append(word)
return [word for word in word_list if len(hash_dict[hasher(word)]) > 1]
if __name__ == '__main__':
with open('wordsEn.txt') as f:
w_list = f.read().split()
anagram_finder(w_list)
I used a library called profiling, and it can be installed with a simple pip install. After profiling the above code, I found that my hasher function was actually making the the whole process a lot slower, because it was being called twice.
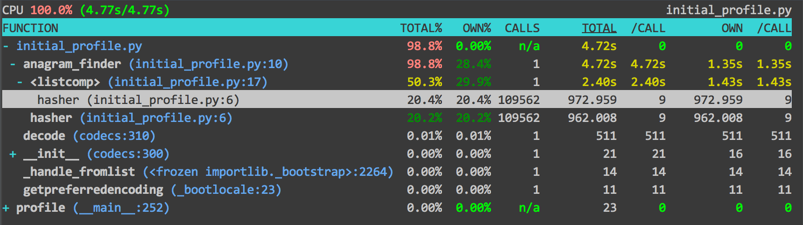
So, my first attempt (like a good pythonista) was to use functools.lru_cache. That attempt failed spectacularly.
from collections import defaultdict
from functools import lru_cache
@lru_cache()
def hasher(w):
return "".join(sorted(w))
def anagram_finder(word_list):
hash_dict = defaultdict(list)
for word in word_list:
hash_dict[hasher(word)].append(word)
return [word for word in word_list if len(hash_dict[hasher(word)]) > 1]
if __name__ == '__main__':
with open('wordsEn.txt') as f:
w_list = f.read().split()
anagram_finder(w_list)
This is because there were excessive calls being made all over the place. Even increasing the size of the cache from lru_cache() which has a default if 128 to lru_cache(11000) which is roughly the size of the word list I'm using. In fact, increasing the lru_cache size to such an amount slowed down the program so much that I didn't wait for it to finish, but the root problem was the same; too many calls were being made all over the place.
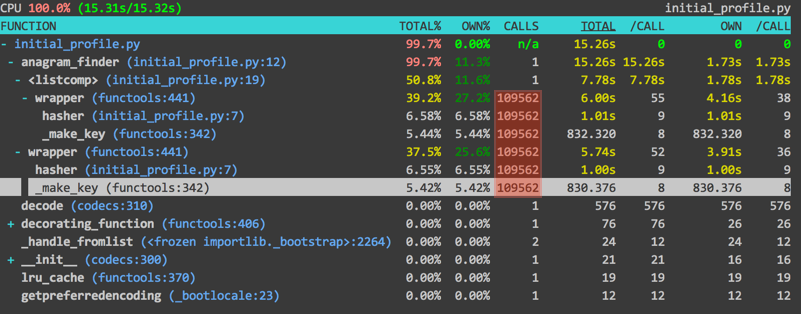
So, to compare the two programs, with lru and without lru, we can see that the program without lru was significantly faster than the one with lru (4.77 seconds to 15.31 seconds. With the failure or lru_cache as a feasible solution, I decided to just use a normal dictionary to store hashes. In our original attempt, hasher was being called twice, once to add words to the dictionary, and then in the list comprehension. Why not just use a dictionary to store the hash and the word?
from collections import defaultdict
def hasher(word):
return "".join(sorted(word))
def anagram_finder(word_list):
hash_dict = defaultdict(list)
hashes = {}
for word in word_list:
hashes[word] = hasher(word)
hash_dict[hashes[word]].append(word)
return [word for word in word_list if len(hash_dict[hashes[word]]) > 1]
if __name__ == '__main__':
with open('wordsEn.txt') as f:
w_list = f.read().split()
anagram_finder(w_list)
We just create a new dictionary, hashes to store all our hash and word pairs. This resulted in a speedup.
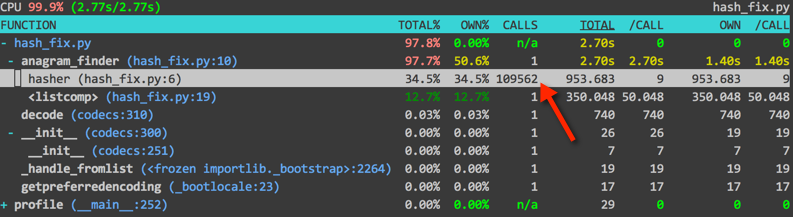
A Vector Approach to Hashing
Another approach to hashing would be to use a vector to determine the number of letters that appear in a word. This is better explained through code:
def hasher(word):
h = [0] * 26 # 1
for c in word:
h[ord(c) - ord('a')] += 1 # 2
return tuple(h) # 3
In 1, we create a list of length 26, having all its values initialized to 0. In 2, we calculate the rank of the letter in the english alphabet using ord(c) - ord(a). We use this rank as the index of our list. We then add 1 to the value of the index. In other words we are merely counting the frequency of the letters in a word; very similar to a histogram.
The above is O(n) compared to the O(n log(n)) solution that sorting a string gives us (n is the number of characters in the word here). However, considering that the average size of a word in the english language is actually 5 and the average size of a word in my wordsEn.txt file is 8, O(n) actually becomes the smaller problem here, and the constant time that is required to create a list of 26 items is the bigger problem. In other words, its O(26) for list creation and initiation. Its O(n) for creating the rank and its O(26) for creating the tuple.
Compare that to O(n log(n)) worst case for using sorted. In this particular use case since n is very low, the better option is to use sorted.
The Final Frontier
The best solution to this problem however is not one of my own making, but rather one that a friend of mine (Alexander) provided me with. My solution actually is superfluous in many cases, but the following cuts straight to the point:
from collections import defaultdict
from itertools import izip
def get_anagrams(words):
normalized = [''.join(sorted(w)) for w in words] # 1
d = defaultdict(int) # 2
for n in normalized: # 3
d[n] += 1 # 4
return [w for w, n in izip(words, normalized) if d[n] > 1] # 5
The genius of this approach is to use collections.defaultdict with int as the factory. This basically means that you have a smaller memory footprint. So, in 1, we get a list of hashed values (which he calls normalized). In 2, we create a defaultdict of int, this means that all the keys will have an initial value of 0.
In 3, we loop over all the normalized/hashed values. 4 is where the magic happens. So, there will be duplicates in normalized, and we are going to count the number of times each of those normalized values appear.
In 5, we zip over the initial word list, words and normalized. Remember, that all the words are normalized. All we do then is simply check to see if the number of times the normalized value of the word appears in d. If there's more than one occurrence, we add the word to the final list in this list comprehension.
But There's An Import For That
In the very beginning, I used collections.Counter, to provide the worst possible solution to the problem. But, I think this time, we can actually use collections.Counter correctly, because 2, 3 and 4 can be shortened to just Counter(normalized). So the final final (gosh, that feels javaish) version is:
def get_anagrams(words):
normalized = [''.join(sorted(w)) for w in words]
d = Counter(normalized)
return [w for w, n in izip(words, normalized) if d[n] > 1]
Lessons Learnt
- Hash Maps are very important. Learn to use them properly.
- When making an algorithm don't think standard library, think of finding the best algorithmic solution.
- After you've found the algorithmic solution try optimizing it using the standard library.
- Quadratic time is worse than you can imagine.
- Complexity analysis alone is a blunt instrument so always profile.
- Just because an algorithm has better worst case complexity doesn't mean that its the best one for the job.
- Sometimes our brains stop working under pressure. Take a deep breath, stop worrying about what will happen if you don't solved the problem and focus on all the good things that will happen if you do.
Acknowledgments
Ashwin (@inspectorG4dget) for helping me answer this question and explaining the vector approach to hashing. Ashwin's help has been paramount to my understanding.
To my interviewer for giving me a very good question, and to Ridwan (@hjr265) for pointing out flaws in my solution and for encouraging me to write a blog post on this problem.
Alexander (@metaprogrammer) for proof reading this post and providing me with the optimal solution to this problem.[4]
| [1] | Python Hash Algorithms explains in detail how the different hash functions in Python actually work. |
| [2] | wordsEn.txt is the list I used. |
| [3] | Using defaultdict in Python is a great writeup on how to use defaultdict. It explains the concept of a factory as well. |
| [4] | Alexander Kozlovsky is the creator of Pony ORM. |